'AI 최고위 전략대화'와 '깃허브'서 멀티모달 언어모델 '허니비' 선보여
멀티모달 언어모델의 핵심인 데이터와 훈련용 코드는 내달 공개 예정

[월요신문=박지영 기자]카카오가 이미지를 인식해 텍스트로 답하는 AI 멀티모달 언어모델(MLLMs) '허니비(Honeybee)'를 공개했다. 이를 개발한 카카오의 AI연구전문 자회사 카카오브레인에서는 글로벌 MLLMs 발전 차원에서 허니비 코드를 '깃허브(Github)'에 공개하기도 했다. 다만, 현재까지 일부 데이터와 코드만 오픈된 상태로 핵심코드는 내달 공개할 계획인 것으로 알려졌다.
19일 과학기술정보통신부 주관으로 열린 제5차 인공지능 최고위 전략대화에서 카카오가 허니비를 공개했다. 이날 행사에는 네이버, 삼성전자, KT 등 각계 기업 대표들이 참석해 AI 일상화에 따른 향후 전략 등이 논의됐다.

이날 행사에서 정신아 카카오 대표 내정자는 "과거 모바일 시대의 흐름에서는 기업들이 각자 열심히 개발하면 승자가 나왔지만, AI는 기업 간 협업과 생태계의 발현이 중요하다. 정부도 함께 정책을 마련해주시면 좋겠다"고 밝혔다. 이어 AI를 이루는 핵심 요소로 '파운데이션 모델, 트레이닝용 데이터, 인프라' 등 3가지를 꼽았다.
카카오가 공개한 허니비 MLLMs는 이미지와 명령어(프롬프트)를 입력하면, 텍스트로 답변하는 모델로 텍스트로만 입⋅출력하는 대규모 언어모델에서 확장된 형태라고 할 수 있다.
단일 모드(예: 텍스트만) 대신 여러 가지 형태의 데이터(예: 텍스트, 이미지, 오디오 등)를 동시에 처리하고 이해할 수 있는 능력을 가지고 있으며 이러한 모델들은 대규모 데이터셋에서 학습된다. 이를 통해 복잡한 언어 패턴, 이미지 내용, 음성 특성 등을 분석하고 이해할 수 있다는 장점이 있다.
따라서 이미지와 텍스트를 모두 입력할 수 있기에 이미지에 담긴 장면을 묘사하거나 이미지와 텍스트가 혼합된 콘텐츠에 관한 질문을 이해하고 답변할 수 있다.

예를 들어 위 사진을 두고 '허니비'에 '농구 경기 중인 두 명의 선수' 이미지와 함께 '왼쪽 선수는 몇 번 우승했나요?'라는 질문을 영어로 입력하면, '허니비'가 입력된 이미지 내용과 질문을 종합적으로 이해하고 "노란색 저지를 입은 왼쪽 선수는 코비 브라이언트 (Kobe Bryant) 이다. 코비 브라이언트는 경력 중 5회 우승했고, 모두 로스앤젤레스 레이커스에서 우승했다"라고 답변을 생성해낸다.
또한, 카카오브레인의 차준범, 강우영, 문정환, 노병석은 'Honeybee: Locality-enhanced Projector for Multimodal LLM(허니비: 멀티모달 LLM을 위한 로컬리티 강화 프로젝터)' 제목의 논문을 지난해 12월 코넬대학교(Cornell University)가 운영하는 논문 공개 사이트 '아카이브(arXiv)'에 게재했다.
논문에는 "시각적 지시 조정(visual instruction tuning) 기술의 진보와 중요성에도 불구하고, 이는 상대적으로 덜 탐구되었다"라고 지적하며 "우리는 광범위한 실험을 통해, 고성능 MLLM 개발을 밝혀냈다"라고 설명했다.
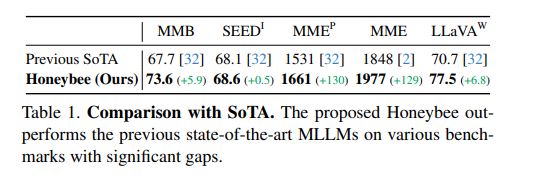
이들은 "우리가 개발한 MLLM인 허니비는 'MME', 'MMBench', 'SEED-Bench' 등 다양한 벤치마크(성능 실험)에서 기존의 최첨단 방법들을 현저히 능가한다"고 자신감을 드러냈다. 실제 허니비는 MLLM 모델의 지각 능력과 인지 능력을 평가하여 포괄적인 평가를 내리는 'MME(Multilingual Model Evaluation)' 벤치마크에서는 2800점 만점 중 1977점을 받은 것으로 전해졌다.
카카오브레인의 최근 발표는 기술 공유와 협력의 모범 사례로도 뽑히고 있다. 카카오브레인 측에서 현재까지 공개된 멀티모달 언어모델 수가 적고 학습 방법 역시 자세히 공개되지 않아 개발이 어렵다는 점에 착안, '허니비'의 소스코드를 공개하기로 결정했기 때문이다.
이에 대해 김일두 카카오브레인 각자 대표는 "허니비 모델의 추론을 가능하게 하는 코드도 깃허브에 공개했으며, '허니비'를 활용한 각종 서비스 확장을 고려 중"이라고 밝혔다.
다만 현재까지 깃허브 사이트에서는 관련 코드를 확인할 수 있었으나, 데이터와 모델이 데이터를 어떻게 처리하고 학습하는지 알 수 있는 훈련용 코드는 아직 공개되지 않았다.
이와 관련 2주 전, 깃허브에서 한 유저가 "데이터와 훈련용 코드는 언제 공개할 것이냐"라고 질문했는데 이에 대해 카카오브레인 개발자인 차준범씨는 "공개 날짜는 아직 정확히 결정되지 않았으나 대략 다음 달에 공개할 계획이다"라고 답변했다.